Программное обеспечение для Интеллектуальных Транспортных Систем (ИТС)
Подсистема обеспечивает прием и обработку всего объема доступной метеорологической и экологической информации с метеорологических станций и комплексов экологической обстановки окружающей среды , выборку данных, расчет специализированных данных, прогнозов прогностических сервисов и нейросети, интеграцию с верхнеуровневой интеграционной платформой ИТС, передачу необходимых Пользователю данных в Модули ИТС и подсистемы интеллектуальной транспортной системы (ИТС) по средством API.
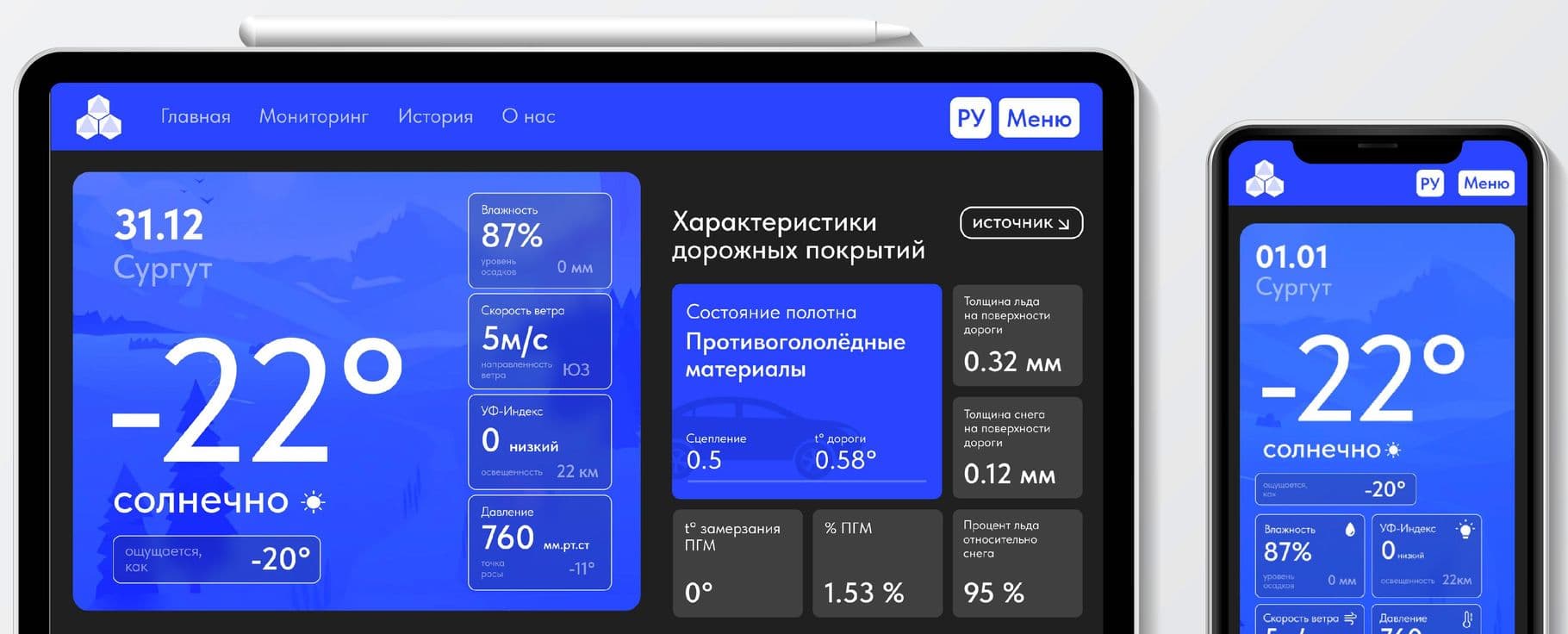
Визуализация на картографическом слое метеорологических комплексов с привязкой к координатам.
Стоимость программного обеспечения
"Краммерти. Подсистема метеомониторинга":
Оформление лицензии:
Передача неисключительного права на использование программы с подписанием лицензионного соглашения.
Мероприятия сопровождающие оформление Лицензии:
- внедрение подсистемы метеомониторинга, развертывание подсистемы на сервере Заказчика;
- интеграция с ИТС Заказчика;
- подключение существующих метеорологических комплексов Заказчика в подсистему;
- гарантия 12 мес. включая сопровождение;
- обучение бесплатно;
Стоимость формируется при обследовании и локализации.
(по ссылке представлен функционал "Горожанин" для ознакомления с полной версией с функционалом Пользователя и Администратора запросите презентацию удобным для Вас способом:
чат на сайте, контактная форма, телефонный звонок, электронная почта)
В 2025 году программа полностью была обновлена в части UI/UX архитектуры, обновленная документация представлена здесь
При необходимости заключаем договор на постгарантийное сопровождение программного обеспечения.
Стоимость сопровождения зависит от решаемых задач (с обслуживанием оборудования/ без обслуживания и т.д.)
Обслуживание периферийного оборудования: демонтаж, транспортировка на завод производитель, проведение профилактических работ, очередная поверка, транспортировка на место монтажа, монтаж, настройка передачи данных;
Наличие сервиса обеспечивающего выезд на место монтажа оборудования для решения задач по работоспособности, демонтажу и ремонту.
Стоимость сопровождения зависит от решаемых задач (с обслуживанием оборудования/ без обслуживания и т.д.)
Обслуживание периферийного оборудования: демонтаж, транспортировка на завод производитель, проведение профилактических работ, очередная поверка, транспортировка на место монтажа, монтаж, настройка передачи данных;
Наличие сервиса обеспечивающего выезд на место монтажа оборудования для решения задач по работоспособности, демонтажу и ремонту.
Где подсистема метеомониторинга используется?
Кроссплатформенная программа для ЭВМ "Краммерти. Подсистема метеомониторинга" используется как Подсистема метеомониторинга в Интеллектуальных транспортных системах (ИТС), Единых платформах управления транспортной системой (ЕПУТС), как отдельная самостоятельная программа ЭВМ, в целом для интеграций с любыми внешними системами и подсистемами по средством API, предусматривается как коммерческое так и образовательное использование.
Функциональные возможности подсистемы метеомониторинга:
Виды интерфейса и функционал ранжируется по ролям: Горожанин, Пользователь, Администратор (Горожанин - свободный доступ в веб приложение - публичная часть, Пользователь эксплуатирующего систему предприятия, Администратор эксплуатирующего систему предприятия);
Визуальное оформление тем: Светлая, Темная
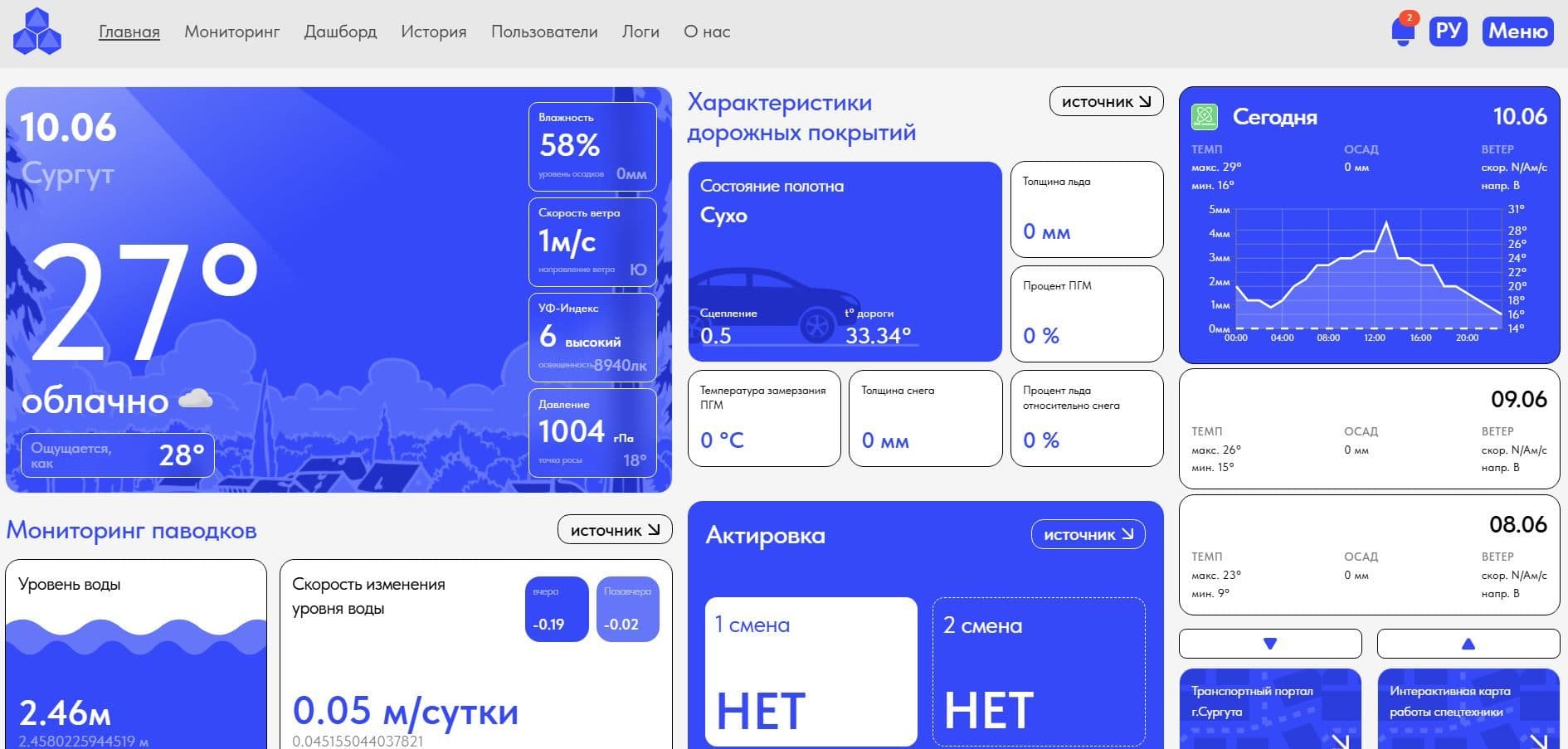
1. Главный режим: предоставляет сводную информацию о всех метеоданных на данный момент, среднесрочный прогноз на 7 суток, прогноз машинного обучения 7 суток ("Краммерти. Модуль прогнозирования временных рядов"), информацию о состоянии поверхности дороги, информацию о наличии актированных дней (сезон - зимний), рекомендации для коммунальных служб города на основе анализа данных получаемых с измерительного периферийного оборудования.
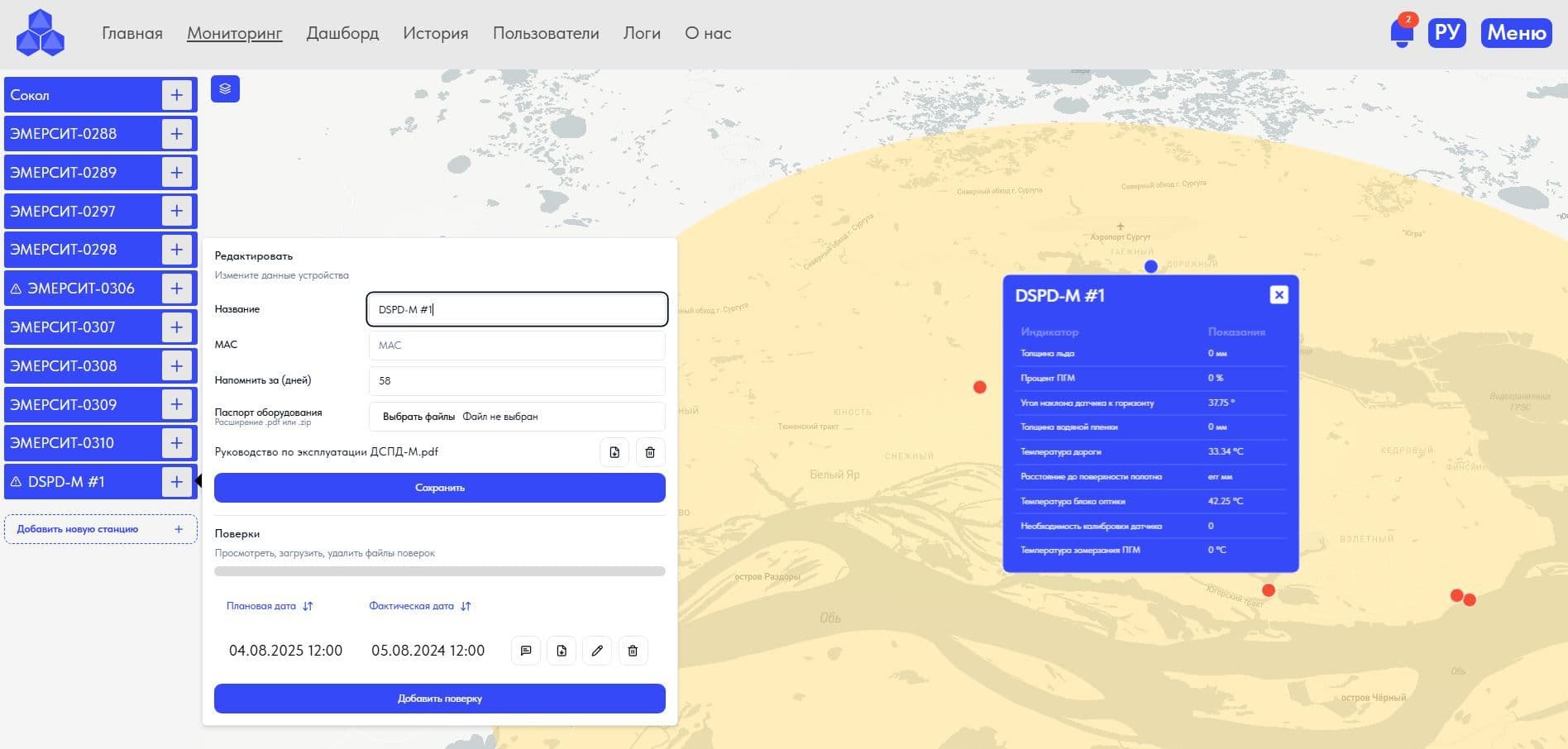
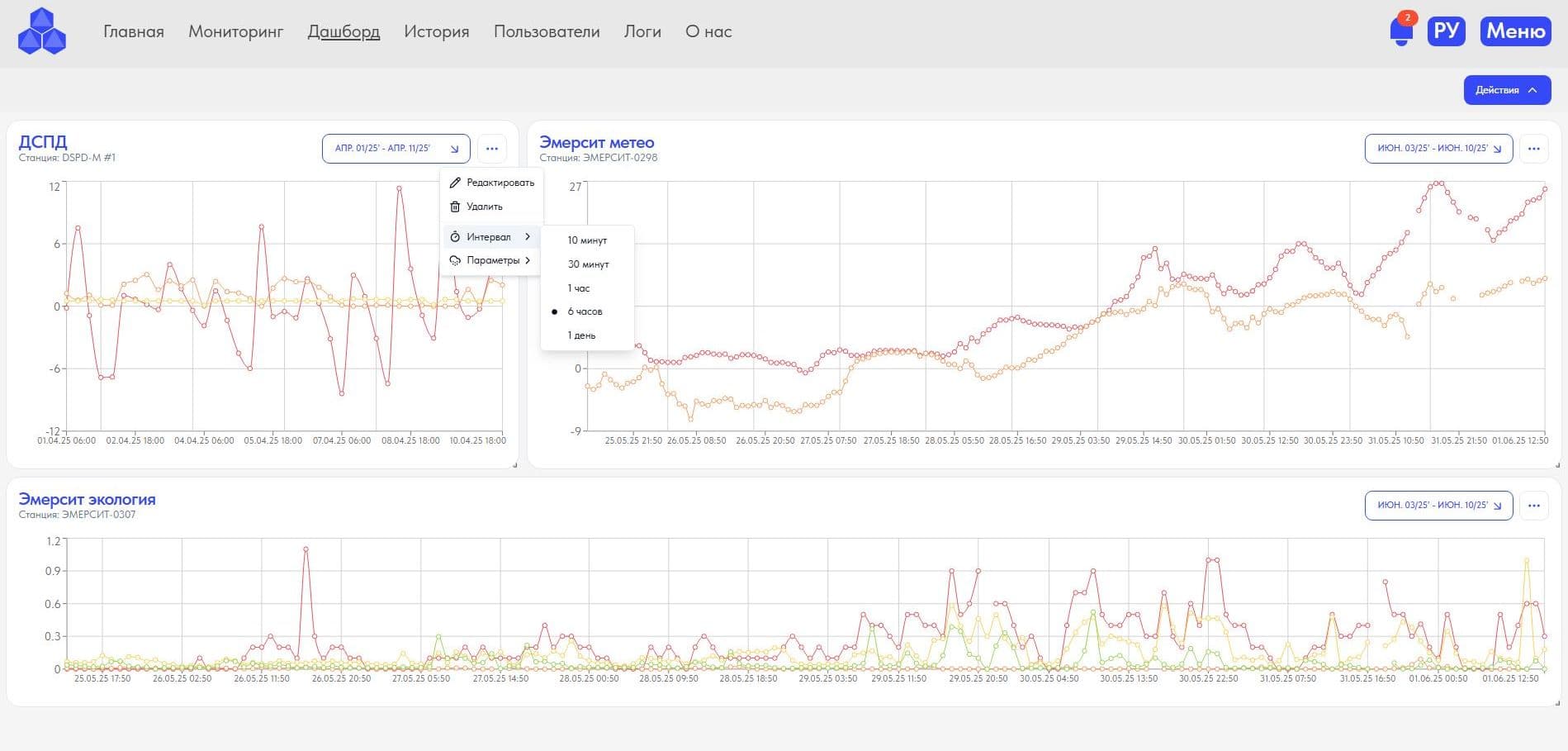
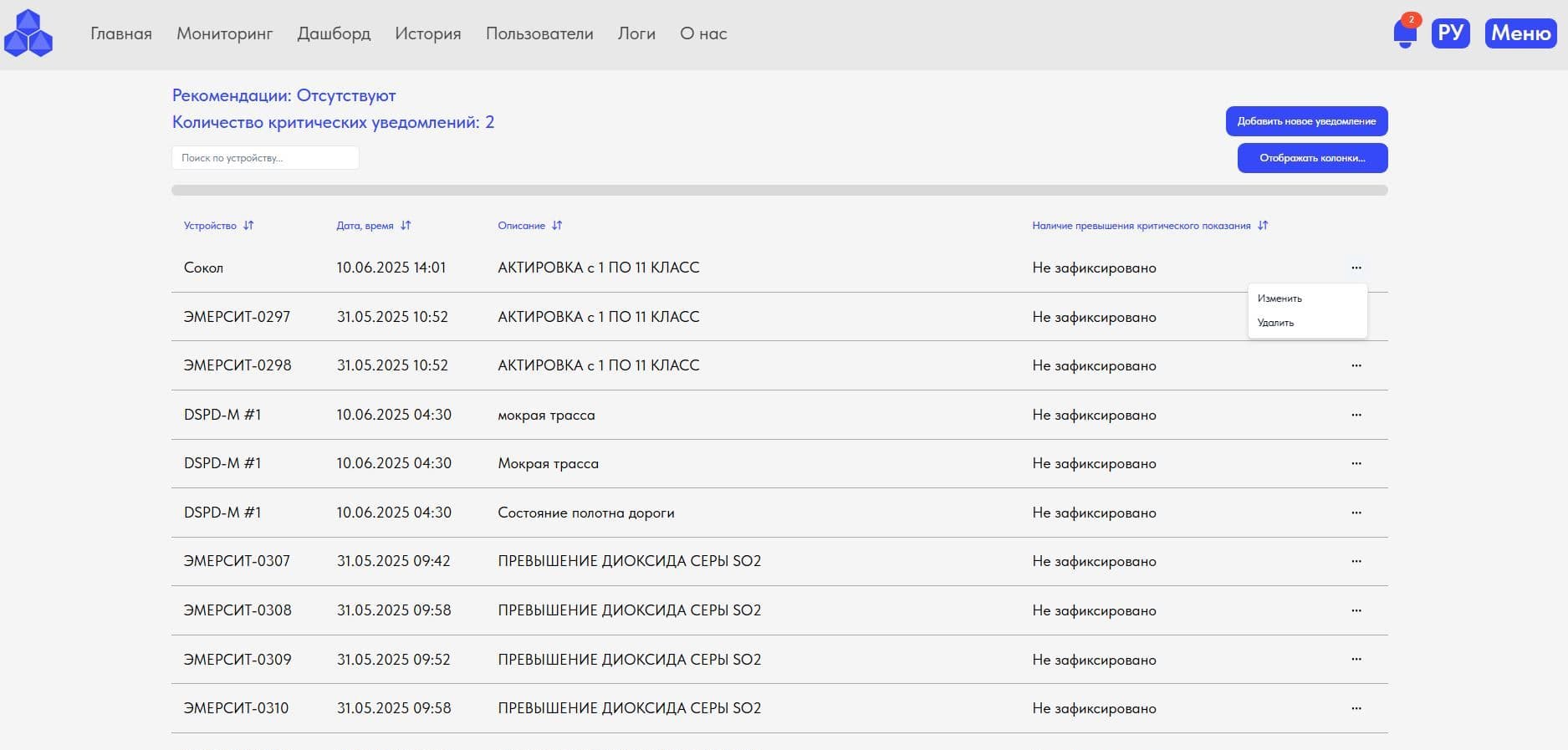
2. Режим "Мониторинг": визуализация расположения оборудования на картографическом слое в привязкой к карте (широта, долгота), выбора оборудования указателем мыши на карте и в перечне;
Контроль работоспособности периферийного оборудования метеостанций и экологических комплексов, контроль работоспособности глубокий, а именно Пользователь в реальном времени получает информацию о работе не только оборудования в целом, но и в разрезе каждого из измерительных датчиков в составе оборудования, с наличием информации когда последний раз тот или иной датчик были на связи (визуализация даты и времени крайней передачи данных выбранного датчика), возможность скачать поверку, посмотреть, отредактировать данные по поверке, удалить поверку и т.д.;
Контроль работоспособности периферийного оборудования метеостанций и экологических комплексов, контроль работоспособности глубокий, а именно Пользователь в реальном времени получает информацию о работе не только оборудования в целом, но и в разрезе каждого из измерительных датчиков в составе оборудования, с наличием информации когда последний раз тот или иной датчик были на связи (визуализация даты и времени крайней передачи данных выбранного датчика), возможность скачать поверку, посмотреть, отредактировать данные по поверке, удалить поверку и т.д.;
Визуализация данных в реальном времени поступающих от измерительного оборудования (метео, экология);
Карточка оборудования содержит полное описание оборудования, с возможностью подгрузки и хранения паспорта оборудования (.pdf, .zip), раздел поверки оборудования позволяет хранить свидетельства о поверках оборудования с контролем текущей даты поверки и плановой на будущие периоды с функцией напоминания о предстоящих поверках;
Тепловая карта - визуализация температурного растра на картографическом слое;
Карточка оборудования содержит полное описание оборудования, с возможностью подгрузки и хранения паспорта оборудования (.pdf, .zip), раздел поверки оборудования позволяет хранить свидетельства о поверках оборудования с контролем текущей даты поверки и плановой на будущие периоды с функцией напоминания о предстоящих поверках;
Тепловая карта - визуализация температурного растра на картографическом слое;
3. Режим "Дашборд": конструктор виджетов позволяющий формировать виджеты и работать с данными во времени (календарь от и до, часы, минуты) в разрезе оборудования > датчиков на борту > параметров > интервала передачи данных (10 мин., 30 мин., 1 час, 6 часов, 1 день); Располагать виджеты по своему усмотрению, меняя размер и местоположение на экране;
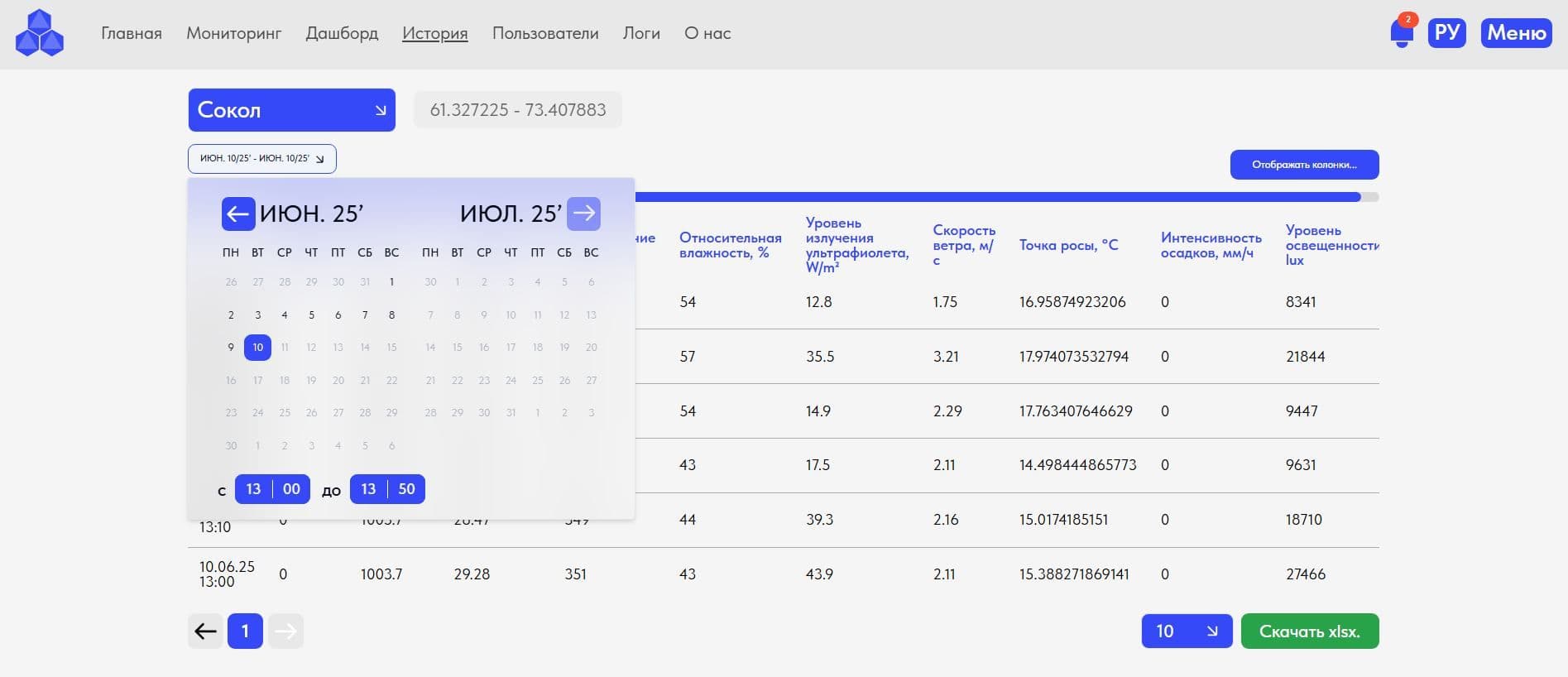
4. Режим "История": Работа и выгрузка в формате .xlsx исторических данных (календарь от и до, часы и минуты) в разрезе оборудования и всех доступных параметров;
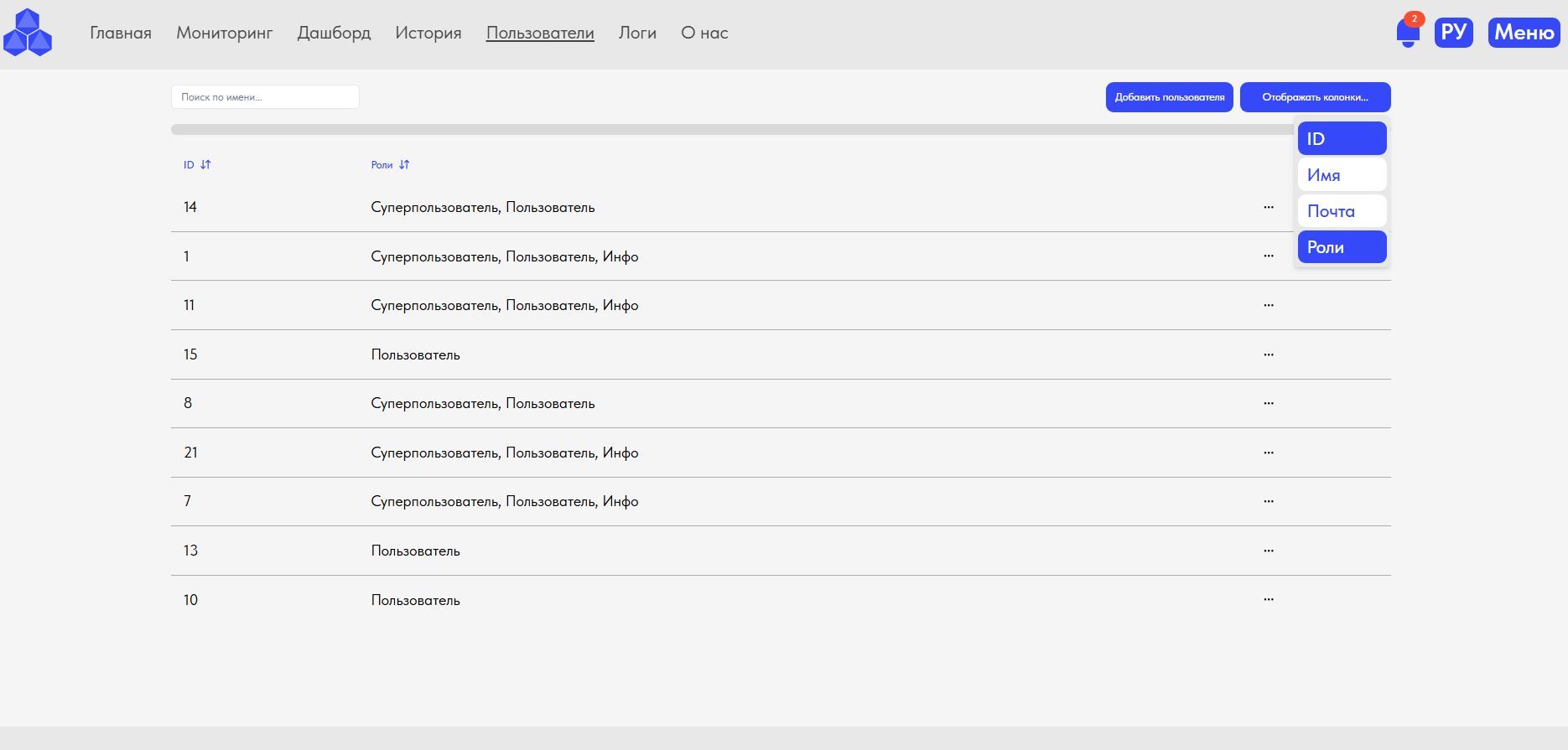
5. Режим "Пользователи": Создание и редактирование учетных данных Пользователей (Администраторов) с полями: Почта, Имя, Пароль, Номер телефона, Организация, Должность, Роли: Пользователь, Администратор, Инфо) Инфо - для Руководителя (ей) эксплуатирующего систему предприятия позволяющая получать рекомендации и критические уведомления на эл. адрес;
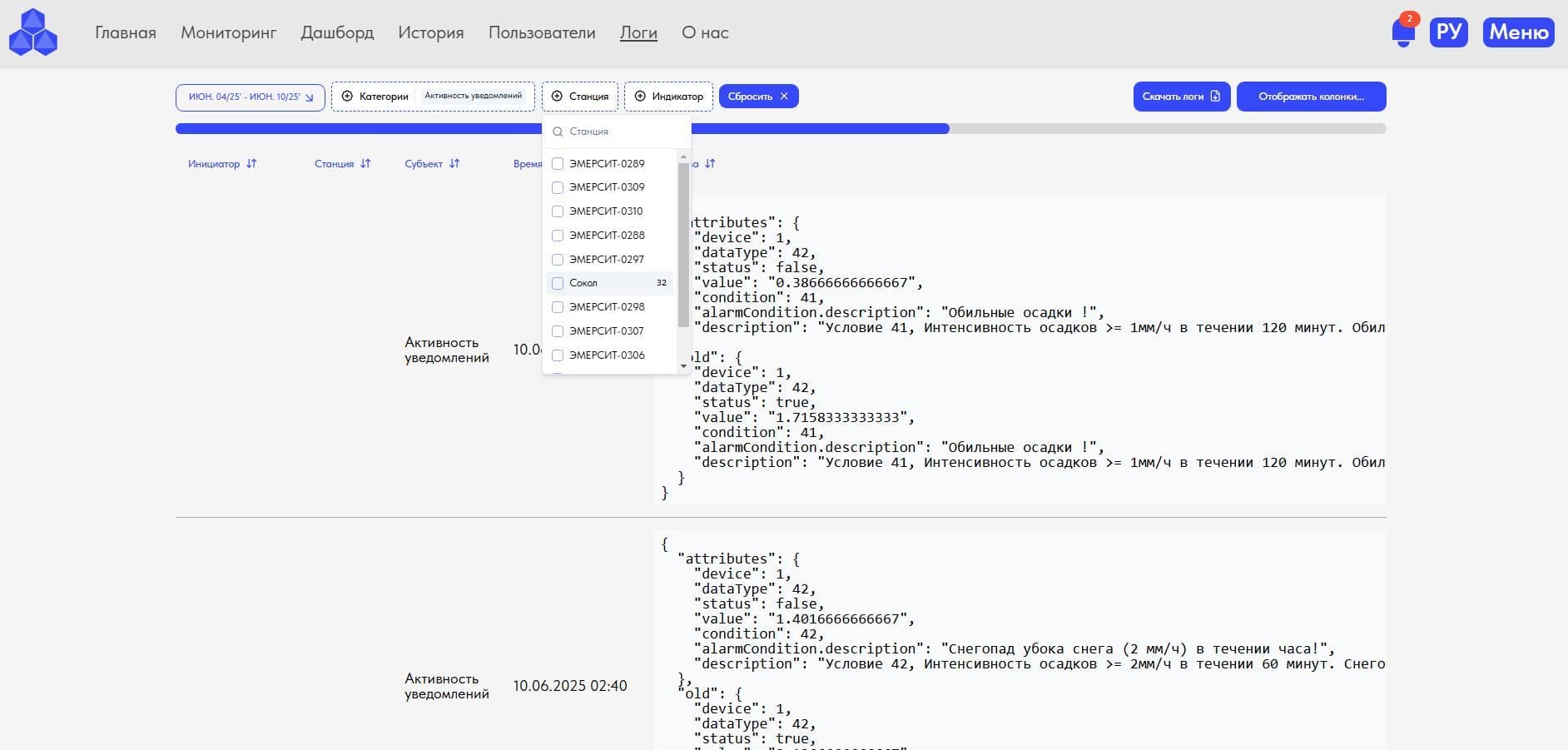
6. Режим "Логи": для Администраторов системы: полный контроль действий пользователей, включая самих Администраторов в системе, глубокая отчетность с многочисленными фильтрами и выгрузкой в .xlsx;
7. Режим "Уведомления": конструктор критических уведомлений с возможностью создавать, редактировать, удалять критические уведомления, создание уведомлений используя все виды параметров (отслеживаемый индикатор), создание математических и логических условий сработки, определением значения сработки в продолжительности присутствия в минутах с описанием уведомления;
Подрежим "Рекомендации" содержит алгоритмы выдачи рекомендаций коммунальным службам города таких как Обработка поверхности полотна дороги ПГМ, Вывод техники на уборку снега, Высокая обводненность дороги - водоотведение и др.
8. Режим "О программе": информация о разработчике ПО, версия, телефон поддержки, ссылка на форму поддержки на сайте разработчика.
Интерфейс подсистемы метеомониторинга
Сопроводительная документация программного обеспечения "Краммерти. Подсистема метеомониторинга"
Перечень сопроводительной документации содержится в Руководстве Пользователя и передается Заказчиу (Пользователю) при покупке ПО.


С учетом рефакторинга 2025г.
Руководство Пользователя v.2025.1.0 май 2025г.Модуль прогнозирования временных рядов
Программа разработана для нужд оперативного мониторинга и планирования, предоставляя как основной прогноз на заданный горизонт, так и расчетную температуру "по ощущениям" (с учетом ветро-холодового индекса). Программа интегрирует данные из внутреннего и/или внешнего API исторических наблюдений необходимых параметров (метеостанции, и иное имеющееся на балансе Заказчика измерительное оборудование и т.д. временные ряды) а также учитываются внешние прогностические данные сторонних сервисов (если это необходимо). Подробное описание содержится в Руководстве Пользовтеля (документ выложен ниже)
Стоимость Модуля прогнозирования: входит в комплект поставки подсистемы метеомониторинга.
Стоимость программного обеспечения
"Моуль прогнозирования временных рядов":
включает в себя:
Оформление лицензии:
Передача неисключительного права на использование программы с подписанием лицензионного соглашения.
Мероприятия сопровождающие оформление Лицензии:
- внедрение программы с развертыванием на сервере заказчика (системные требования изложены в документе Инструкция по установке), интеграцию и настройку потока данных временных рядов;
- определение и решение задач;
- адаптация данных Заказчика и настройка гиперпараметров модели;
- достижение поставленной производительности;
- адаптация данных Заказчика и настройка гиперпараметров модели;
- достижение поставленной производительности;
- гарантия 12 мес. включая сопровождение;
- после гарантийного срока возможно заключение договора на сопровождение программного обеспечения;
- обучение бесплатно;
Где применяется модуль прогнозирования
Программа для ЭВМ «Краммерти. Модуль прогнозирования временных рядов» (далее система) предназначена для автоматизированного краткосрочного прогнозирования временных рядов метеорологических параметров. Разработка данного модуля произведена в рамках развития проекта по прогнозированию метеорологических параметров поставляется как в составе «Краммерти. Подсистема метеомониторинга» так и как отдельный программный продукт в зависимости от задач - есть временной ряд - есть прогноз.
Функциональные возможности Модуля прогнозирования временных рядов:
1. Сбор и обновление данных:
- автоматическая загрузка исторических данных по заданным параметрам (напр., температура воздуха) с указанных метеостанций через внутренний API (с обработкой пагинации, кэшированием, повторными попытками и обработкой ошибок).
- проверка свежести локально сохраненных исторических данных;
- автоматическая загрузка актуальных прогнозов;
- проверка свежести локальных копий данных;
- автоматическая загрузка исторических данных по заданным параметрам (напр., температура воздуха) с указанных метеостанций через внутренний API (с обработкой пагинации, кэшированием, повторными попытками и обработкой ошибок).
- проверка свежести локально сохраненных исторических данных;
- автоматическая загрузка актуальных прогнозов;
- проверка свежести локальных копий данных;
2. Хранение данных:
- сохранение загруженных исторических данных, гиперпараметров, метрик, графиков оучения и прогноза в локальные файлы;
3. Подбор гиперпараметров модели нейросети LSTM методом HPO (Hyper Parameter Optimization):
- использование фреймворка Optuna для автоматического поиска оптимальной комбинации гиперпараметров LSTM-модели (количество нейронов, скорость обучения, функции активации, параметры регуляризации, длина входной последовательности и т.д.) на основе заданных диапазонов в hyperparameters.json;
- применение (на этапе HPO) функции потерь, которая учитывает отклонение от фактических данных;
4. Обучение модели:
- обучение финальной LSTM-модели на предобработанных исторических данных с использованием лучших гиперпараметров, найденных Optuna;
- использование стандартной и кастомной функции потерь Huber для обучения финальной модели (не зависит от сторонних прогностических данных на этом этапе);
- применение механизма EarlyStopping для предотвращения переобучения;
- использование фреймворка Optuna для автоматического поиска оптимальной комбинации гиперпараметров LSTM-модели (количество нейронов, скорость обучения, функции активации, параметры регуляризации, длина входной последовательности и т.д.) на основе заданных диапазонов в hyperparameters.json;
- применение (на этапе HPO) функции потерь, которая учитывает отклонение от фактических данных;
4. Обучение модели:
- обучение финальной LSTM-модели на предобработанных исторических данных с использованием лучших гиперпараметров, найденных Optuna;
- использование стандартной и кастомной функции потерь Huber для обучения финальной модели (не зависит от сторонних прогностических данных на этом этапе);
- применение механизма EarlyStopping для предотвращения переобучения;
- сохранение метрик и графиков;
5. Сохранение и версионирование моделей:
- сохранение обученных моделей (.keras), соответствующего объекта Scaler (.pkl) и метаданных включая гиперпараметры и метрики в JSON-файл;
- включение метрики SMAPE и даты в имя файла для отслеживания производительности и выбора лучшей модели.
- сохранение обученных моделей (.keras), соответствующего объекта Scaler (.pkl) и метаданных включая гиперпараметры и метрики в JSON-файл;
- включение метрики SMAPE и даты в имя файла для отслеживания производительности и выбора лучшей модели.
6. Генерация прогноза:
- загрузка лучшей (по SMAPE) сохраненной модели и скейлера для целевого параметра;
- генерация прогноза температуры на заданный горизонт с помощью LSTM-модели.
- загрузка актуальных прогнозов прогностических сервисов данных.
- возможность настройки гибкой коррекции прогноза: контроль корректности прогноза сопоставление с прогнозами прогностических сервисов;
- расчет Wind Chill: Вычисление температуры "по ощущениям" на основе скорректированного прогноза температуры и прогноза скорости ветра прогностических сервисов или иных признаков в зависимости от специфики задач;
7. Вывод результатов:
- сохранение итогового прогноза в структурированный JSON-файл с временными метками;
- генерация и сохранение графиков;
8. Автоматизация:
- использование библиотеки schedule для запуска задач по расписанию (обновление данных, переобучение модели, генерация прогноза);
- возможность интеграции с systemd (на Linux) для обеспечения постоянной работы и автоматического перезапуска сервисов (обновления данных/планировщика и API);
9. API для доступа к прогнозу:
- предоставление простого веб-API (на базе Flask), которое по запросу отдает содержимое самого свежего сгенерированного JSON-файла с прогнозом.
- загрузка лучшей (по SMAPE) сохраненной модели и скейлера для целевого параметра;
- генерация прогноза температуры на заданный горизонт с помощью LSTM-модели.
- загрузка актуальных прогнозов прогностических сервисов данных.
- возможность настройки гибкой коррекции прогноза: контроль корректности прогноза сопоставление с прогнозами прогностических сервисов;
- расчет Wind Chill: Вычисление температуры "по ощущениям" на основе скорректированного прогноза температуры и прогноза скорости ветра прогностических сервисов или иных признаков в зависимости от специфики задач;
7. Вывод результатов:
- сохранение итогового прогноза в структурированный JSON-файл с временными метками;
- генерация и сохранение графиков;
8. Автоматизация:
- использование библиотеки schedule для запуска задач по расписанию (обновление данных, переобучение модели, генерация прогноза);
- возможность интеграции с systemd (на Linux) для обеспечения постоянной работы и автоматического перезапуска сервисов (обновления данных/планировщика и API);
9. API для доступа к прогнозу:
- предоставление простого веб-API (на базе Flask), которое по запросу отдает содержимое самого свежего сгенерированного JSON-файла с прогнозом.
Подробнее в документации к программному обеспечению.
Сопроводительная документация программного обеспечения "Краммерти. Модуль прогнозирования временных рядов"
Для подробного ознакомления - ознакомьтесь с документацией.



v.2025.1.0 май 2025г.
Производительность модуля прогнозирования временных рядов
Анализ производительности "Краммерти. Модуль прогнозирования временных рядов"
Разбираем производительность модуля прогнозирования временных рядов от Краммерти
Настройка модели нейросети - это итеративный процесс.
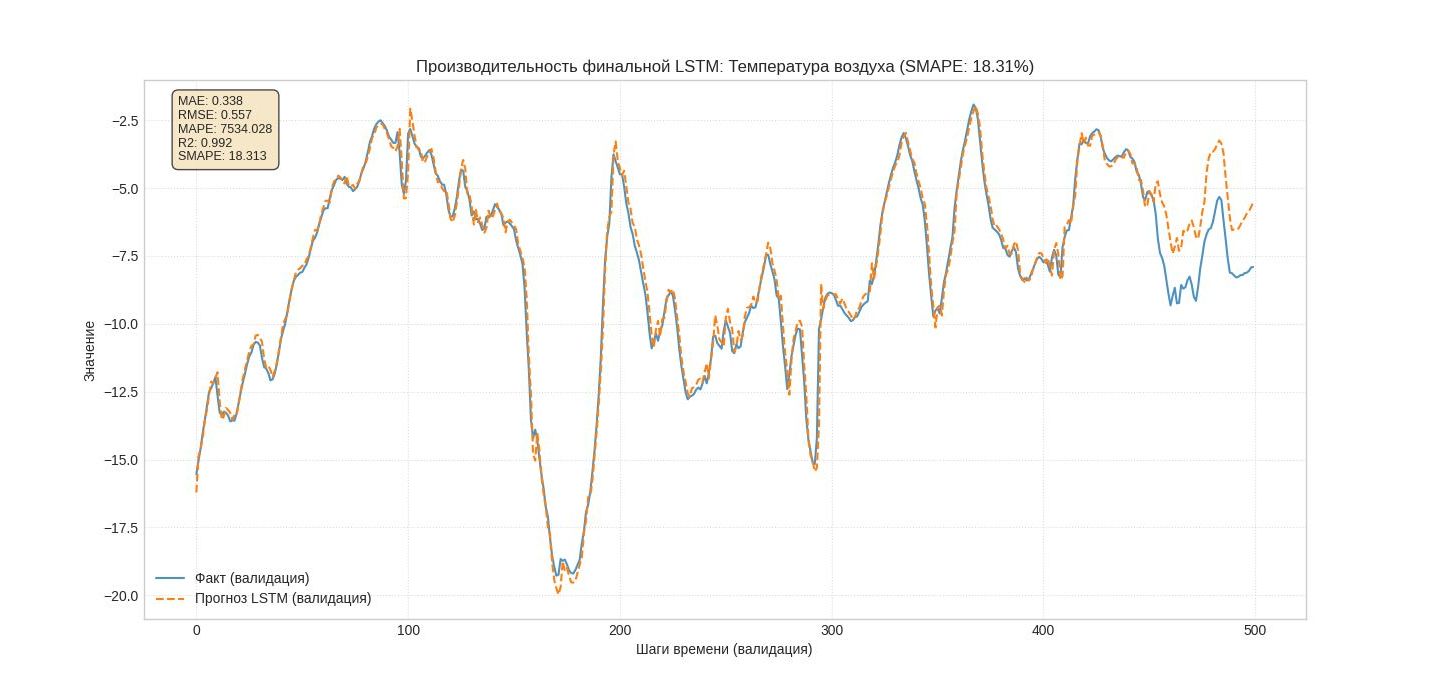
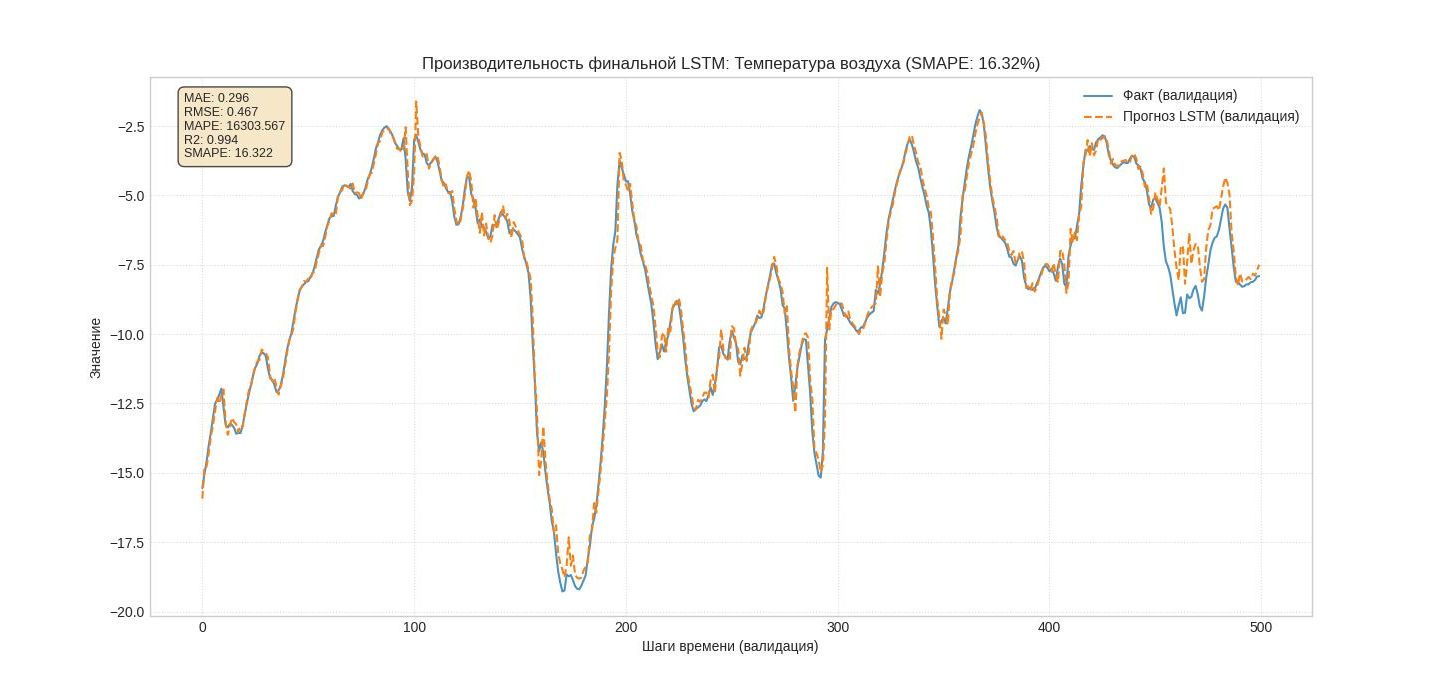
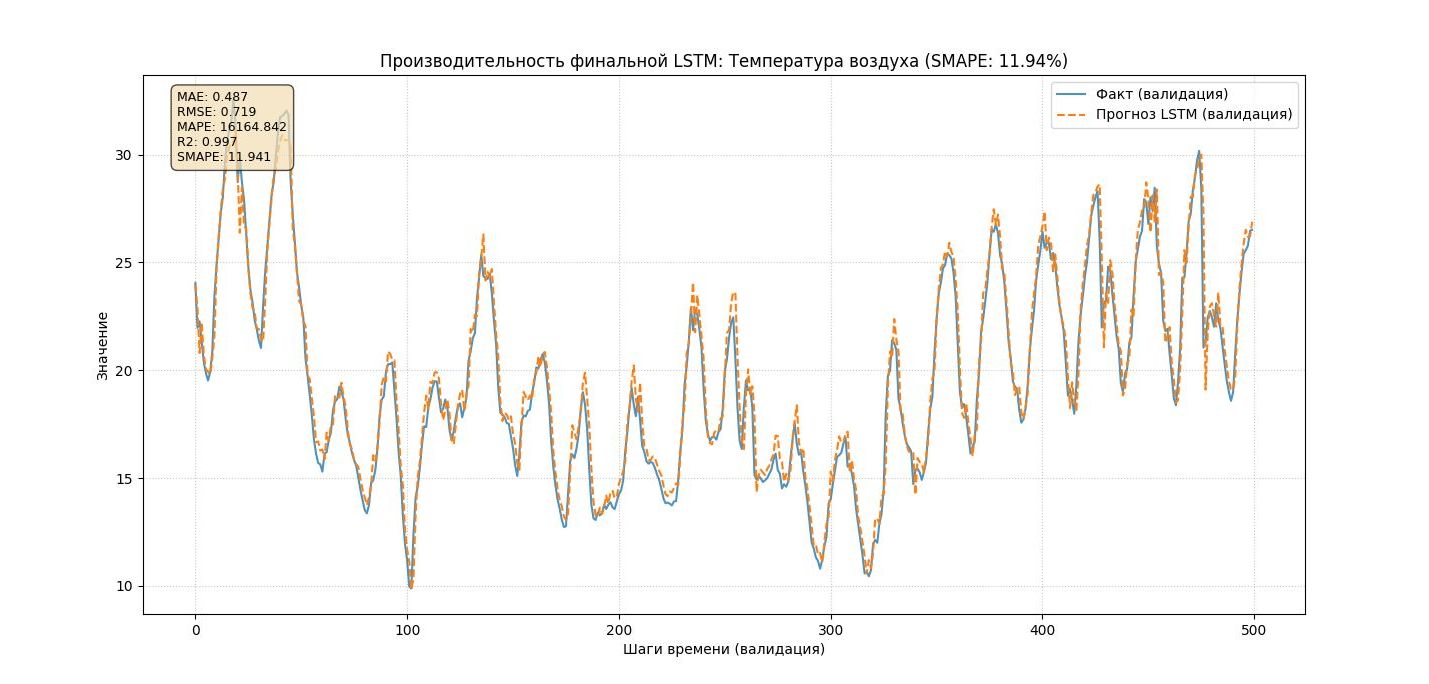
Анализ Графика: Производительность финальной LSTM
Главный вывод:
Модель достаточно точная, что подтверждается как численными метриками, так и визуальным анализом.
1. Анализ числовых метрик (в рамке):
MAE: 0.328 Средняя абсолютная ошибка - низкая. Теперь модель в среднем ошибается всего на 0.33°C.
Это отличный показатель точности.
RMSE: 0.557 Ошибка за большие промахи - незначительная. Модель стабильная.
R2: 0.992 Модель теперь объясняет 99.2% изменчивости данных. Практически идеальное соответствие.
SMAPE: 18.31% Хотя эта метрика менее показательна для температуры, ее невысокий показатель соответствует хорошим тоном.
2. Визуальный анализ графика:
Общее соответствие: Прогноз (оранжевая линия) следует за фактом (синяя линия) на большей части графика. Модель улавливает как плавные суточные циклы, так и резкие, короткие колебания.
Проблема в конце графика (зона для улучшения): Проблема с расхождением прогноза в конце валидационной выборки (после шага ~430). Однако ее характер меняется при скурпулезном подходе к качеству исторических данных.
Прогноз стабильный, но систематически искажает температуру. Он не "паникует", а делает последовательную ошибку из этирации к этирации в одном и том же месте (что важно!) и мы знаем почему. На момент написания данной статьи переключили агрегацию исторических данных с иной метеостанции (слайд 6) Эмерсит (метеостанций) - подали более качественный и глубокий временной ряд исторических даных который содержит данные за период более 4 лет, хотя метеостанция так же поверялись (была в offline), но в разные месяцы разных лет и как видите результат не заставил себя долго ждать, модель обучилась и представила нам иную картину, которая доказала причину ошибок в прошлые этерации - использование нами временного ряда ранее за короткий период времени (всего 20 мес. с провалами в данных). Теперь модель увидела паттерны сезонности на временном отрезке более 4 лет.
Что это означает?
Характер ошибки — это очень важный диагностический признак. Это говорит о том, что модель ранее столкнулась с погодным паттерном, для которого у нее не хватало информации чтобы сделать правильный вывод. Модель видела какие-то входные признаки и, основываясь на своем "опыте", последовательно предсказывала чуть "искаженные" данные по температуре чем есть на самом деле.
Вывод: качество исторических данных и их глубина - это один из фундаментов успеха в работе с прогнозированием временных рядов. В нашем случае мы приводим живой пример и описываем как есть процессы обучения и прогнозирования сначала от метеостанции Сокол (монтаж в 2023г.) факт поверки метеостанции и снятие на обслуживание сократил доступные паттерны (данные) как минимум на 1+ месяца когда АДМС находилась в режиме offline. Но когда мы впустили в модель данные с другой метеостанции смонтированной гораздо раньше (2019г.) и соответственно с более глубокой историей, мы тут же получили более стабильный результат без характерных ошибок.
Что мы видим:
Темно-серая линия (train): Ошибка на обучающих данных.
Голубая линия (validation): Ошибка на валидационных (тестовых) данных, которые модель не использовала для подстройки весов.
Ключевые выводы:
Быстрая сходимость: Обе кривые очень резко падают в первые 5-10 эпох. Это означает, что модель быстро улавливает основные закономерности в данных.
Отсутствие переобучения (Overfitting): Это самый важный вывод. Переобучение происходит, когда ошибка на обучающих данных продолжает падать, а на валидационных начинает расти (кривые расходятся). мы не наблюдаем, наоборот, обе кривые идут почти параллельно друг другу до самого конца. Это говорит о том, что модель учит общие паттерны, а не просто "зазубривает" обучающую выборку.
Валидационная ошибка НИЖЕ обучающей: Обратите внимание, что голубая линия (validation) почти всегда находится ниже серой (train). Это не является ошибкой, а очень хороший знак! Такое часто происходит, потому что мы используем техникурегуляризации, в т.ч. такую как Dropout. Во время обучения Dropout случайным образом "отключает" часть нейронов, усложняя модели задачу. А во время валидации все нейроны работают, и модель показывает свой полный потенциал. То, что она работает на незнакомых данных даже лучше, чем на обучающих (на которых ей мешал Dropout), — признак превосходной обобщающей способности.
Выход на плато: После примерно 20-й эпохи обе кривые становятся очень пологими. Это означает, что модель достигла своего пика производительности для данной архитектуры и данных. Дальнейшее обучение (например, до 200 эпох) почти не принесло бы улучшения и было бы пустой тратой времени. Выбранное количество эпох (~60) является оптимальным.
Главный вывод:
Модель достаточно точная, что подтверждается как численными метриками, так и визуальным анализом.
1. Анализ числовых метрик (в рамке):
MAE: 0.328 Средняя абсолютная ошибка - низкая. Теперь модель в среднем ошибается всего на 0.33°C.
Это отличный показатель точности.
RMSE: 0.557 Ошибка за большие промахи - незначительная. Модель стабильная.
R2: 0.992 Модель теперь объясняет 99.2% изменчивости данных. Практически идеальное соответствие.
SMAPE: 18.31% Хотя эта метрика менее показательна для температуры, ее невысокий показатель соответствует хорошим тоном.
Что такое MAPE и почему она "взрывается"?
Формула MAPE (Mean Absolute Percentage Error) выглядит так:
MAPE = (1/n) * Σ( |(Actual - Forecast) / Actual| ) * 100%
Ключевая проблема находится в знаменателе дроби: / Actual.
Это означает, что ошибка прогноза делится на фактическое значение. Давайте рассмотрим на простом примере, как это ломает логику для температуры:
Сценарий 1: Теплая погода
Фактическая температура (Actual): 20°C
Ваш прогноз (Forecast): 21°C
Абсолютная ошибка: |20 - 21| = 1°C (отличный результат)
Ошибка MAPE для этой точки: (|1| / 20) * 100% = 5%. Звучит разумно.
Сценарий 2: Погода около нуля (самый важный)
Фактическая температура (Actual): 0.5°C
Ваш прогноз (Forecast): 1.5°C
Абсолютная ошибка: |0.5 - 1.5| = 1°C (та же самая прекрасная точность, что и в первом сценарии!)
Ошибка MAPE для этой точки: (|1| / 0.5) * 100% = 200%. Катастрофа!
Сценарий 3: "Апокалипсис" при нулевой температуре
Фактическая температура (Actual): 0°C
Ваш прогноз (Forecast): 1°C
Ошибка MAPE для этой точки: (|1| / 0) * 100% — Деление на ноль! Формула просто не работает.
Что произошло?
Из-за того, что фактическое значение температуры на графике (Actual) много раз было близко к нулю или отрицательным (например, -2°C, -5°C, 1°C), даже крошечная абсолютная ошибка в 0.3°C приводила к гигантским процентным значениям. Эти значения суммировались и дали итоговый MAPE в тысячи процентов.
Вывод: MAPE категорически не подходит для оценки моделей, прогнозирующих величины, которые могут пересекать ноль. Здесь данная метрика присутствует "за компанию".
А как же SMAPE? Почему она тоже не идеальна?
Наша метрика SMAPE равна 18.31%, что выглядит гораздо адекватнее, но все равно кажется большой ошибкой по сравнению с MAE 0.33°C.
Формула SMAPE (Symmetric Mean Absolute Percentage Error) была придумана, чтобы решить проблему MAPE:
SMAPE = (1/n) * Σ( |Forecast - Actual| / ((|Actual| + |Forecast|) / 2) ) * 100%
Она использует в знаменателе среднее от абсолютных значений прогноза и факта. Это решает проблему деления на ноль и делает метрику более стабильной.
Но проблема остается:
Даже в SMAPE, когда и Actual, и Forecast — это малые величины (например, -2°C и -2.5°C), знаменатель будет маленьким, а результат — большим в процентном отношении.
Пример: Actual = -2°C, Forecast = -2.5°C.
Абсолютная ошибка (MAE): 0.5°C (отлично).
Ошибка SMAPE: | -2.5 - (-2) | / ((|-2| + |-2.5|) / 2) = 0.5 / (4.5 / 2) = 0.5 / 2.25 ≈ 22.2%.
Как видите, даже для превосходного прогноза с ошибкой в полградуса, SMAPE может показывать >20%.
Какие метрики использовать и чему доверять?
Для задачи которую мы разбираем (прогноз температуры) иерархия доверия к метрикам должна быть такой:
🥇 MAE (Mean Absolute Error): Самый главный и честный показатель.
Почему: Он интуитивно понятен. MAE = 0.328 прямо говорит: "В среднем моя модель ошибается на 0.33 градуса Цельсия". Это легко интерпретировать и сравнить.
🥈 RMSE (Root Mean Square Error): Отличный второй пилот.
Почему: Он показывает, насколько велики ваши самые большие ошибки. Если RMSE ненамного больше MAE (как в вашем случае: 0.557 против 0.328), это значит, что у модели нет регулярных грубых промахов.
🥉 R² (Коэффициент детерминации): Полезен для общей картины.
Почему: R² = 0.992 говорит о том, что модель объясняет 99.2% всех колебаний температуры. Это подтверждает, что модель в целом очень адекватна.
🗑️ MAPE и SMAPE: Игнорировать или использовать с большой осторожностью.
Почему? : Они не отражают реальную физическую точность прогноза в градусах и могут сильно искажать восприятие качества модели из-за математических особенностей своих формул.
Формула MAPE (Mean Absolute Percentage Error) выглядит так:
MAPE = (1/n) * Σ( |(Actual - Forecast) / Actual| ) * 100%
Ключевая проблема находится в знаменателе дроби: / Actual.
Это означает, что ошибка прогноза делится на фактическое значение. Давайте рассмотрим на простом примере, как это ломает логику для температуры:
Сценарий 1: Теплая погода
Фактическая температура (Actual): 20°C
Ваш прогноз (Forecast): 21°C
Абсолютная ошибка: |20 - 21| = 1°C (отличный результат)
Ошибка MAPE для этой точки: (|1| / 20) * 100% = 5%. Звучит разумно.
Сценарий 2: Погода около нуля (самый важный)
Фактическая температура (Actual): 0.5°C
Ваш прогноз (Forecast): 1.5°C
Абсолютная ошибка: |0.5 - 1.5| = 1°C (та же самая прекрасная точность, что и в первом сценарии!)
Ошибка MAPE для этой точки: (|1| / 0.5) * 100% = 200%. Катастрофа!
Сценарий 3: "Апокалипсис" при нулевой температуре
Фактическая температура (Actual): 0°C
Ваш прогноз (Forecast): 1°C
Ошибка MAPE для этой точки: (|1| / 0) * 100% — Деление на ноль! Формула просто не работает.
Что произошло?
Из-за того, что фактическое значение температуры на графике (Actual) много раз было близко к нулю или отрицательным (например, -2°C, -5°C, 1°C), даже крошечная абсолютная ошибка в 0.3°C приводила к гигантским процентным значениям. Эти значения суммировались и дали итоговый MAPE в тысячи процентов.
Вывод: MAPE категорически не подходит для оценки моделей, прогнозирующих величины, которые могут пересекать ноль. Здесь данная метрика присутствует "за компанию".
А как же SMAPE? Почему она тоже не идеальна?
Наша метрика SMAPE равна 18.31%, что выглядит гораздо адекватнее, но все равно кажется большой ошибкой по сравнению с MAE 0.33°C.
Формула SMAPE (Symmetric Mean Absolute Percentage Error) была придумана, чтобы решить проблему MAPE:
SMAPE = (1/n) * Σ( |Forecast - Actual| / ((|Actual| + |Forecast|) / 2) ) * 100%
Она использует в знаменателе среднее от абсолютных значений прогноза и факта. Это решает проблему деления на ноль и делает метрику более стабильной.
Но проблема остается:
Даже в SMAPE, когда и Actual, и Forecast — это малые величины (например, -2°C и -2.5°C), знаменатель будет маленьким, а результат — большим в процентном отношении.
Пример: Actual = -2°C, Forecast = -2.5°C.
Абсолютная ошибка (MAE): 0.5°C (отлично).
Ошибка SMAPE: | -2.5 - (-2) | / ((|-2| + |-2.5|) / 2) = 0.5 / (4.5 / 2) = 0.5 / 2.25 ≈ 22.2%.
Как видите, даже для превосходного прогноза с ошибкой в полградуса, SMAPE может показывать >20%.
Какие метрики использовать и чему доверять?
Для задачи которую мы разбираем (прогноз температуры) иерархия доверия к метрикам должна быть такой:
🥇 MAE (Mean Absolute Error): Самый главный и честный показатель.
Почему: Он интуитивно понятен. MAE = 0.328 прямо говорит: "В среднем моя модель ошибается на 0.33 градуса Цельсия". Это легко интерпретировать и сравнить.
🥈 RMSE (Root Mean Square Error): Отличный второй пилот.
Почему: Он показывает, насколько велики ваши самые большие ошибки. Если RMSE ненамного больше MAE (как в вашем случае: 0.557 против 0.328), это значит, что у модели нет регулярных грубых промахов.
🥉 R² (Коэффициент детерминации): Полезен для общей картины.
Почему: R² = 0.992 говорит о том, что модель объясняет 99.2% всех колебаний температуры. Это подтверждает, что модель в целом очень адекватна.
🗑️ MAPE и SMAPE: Игнорировать или использовать с большой осторожностью.
Почему? : Они не отражают реальную физическую точность прогноза в градусах и могут сильно искажать восприятие качества модели из-за математических особенностей своих формул.
Заключение по метрикам: Точно, стабильно без явных грубых аномалий.
2. Визуальный анализ графика:
Общее соответствие: Прогноз (оранжевая линия) следует за фактом (синяя линия) на большей части графика. Модель улавливает как плавные суточные циклы, так и резкие, короткие колебания.
Проблема в конце графика (зона для улучшения): Проблема с расхождением прогноза в конце валидационной выборки (после шага ~430). Однако ее характер меняется при скурпулезном подходе к качеству исторических данных.
Прогноз стабильный, но систематически искажает температуру. Он не "паникует", а делает последовательную ошибку из этирации к этирации в одном и том же месте (что важно!) и мы знаем почему. На момент написания данной статьи переключили агрегацию исторических данных с иной метеостанции (слайд 6) Эмерсит (метеостанций) - подали более качественный и глубокий временной ряд исторических даных который содержит данные за период более 4 лет, хотя метеостанция так же поверялись (была в offline), но в разные месяцы разных лет и как видите результат не заставил себя долго ждать, модель обучилась и представила нам иную картину, которая доказала причину ошибок в прошлые этерации - использование нами временного ряда ранее за короткий период времени (всего 20 мес. с провалами в данных). Теперь модель увидела паттерны сезонности на временном отрезке более 4 лет.
Что это означает?
Характер ошибки — это очень важный диагностический признак. Это говорит о том, что модель ранее столкнулась с погодным паттерном, для которого у нее не хватало информации чтобы сделать правильный вывод. Модель видела какие-то входные признаки и, основываясь на своем "опыте", последовательно предсказывала чуть "искаженные" данные по температуре чем есть на самом деле.
Вывод: качество исторических данных и их глубина - это один из фундаментов успеха в работе с прогнозированием временных рядов. В нашем случае мы приводим живой пример и описываем как есть процессы обучения и прогнозирования сначала от метеостанции Сокол (монтаж в 2023г.) факт поверки метеостанции и снятие на обслуживание сократил доступные паттерны (данные) как минимум на 1+ месяца когда АДМС находилась в режиме offline. Но когда мы впустили в модель данные с другой метеостанции смонтированной гораздо раньше (2019г.) и соответственно с более глубокой историей, мы тут же получили более стабильный результат без характерных ошибок.
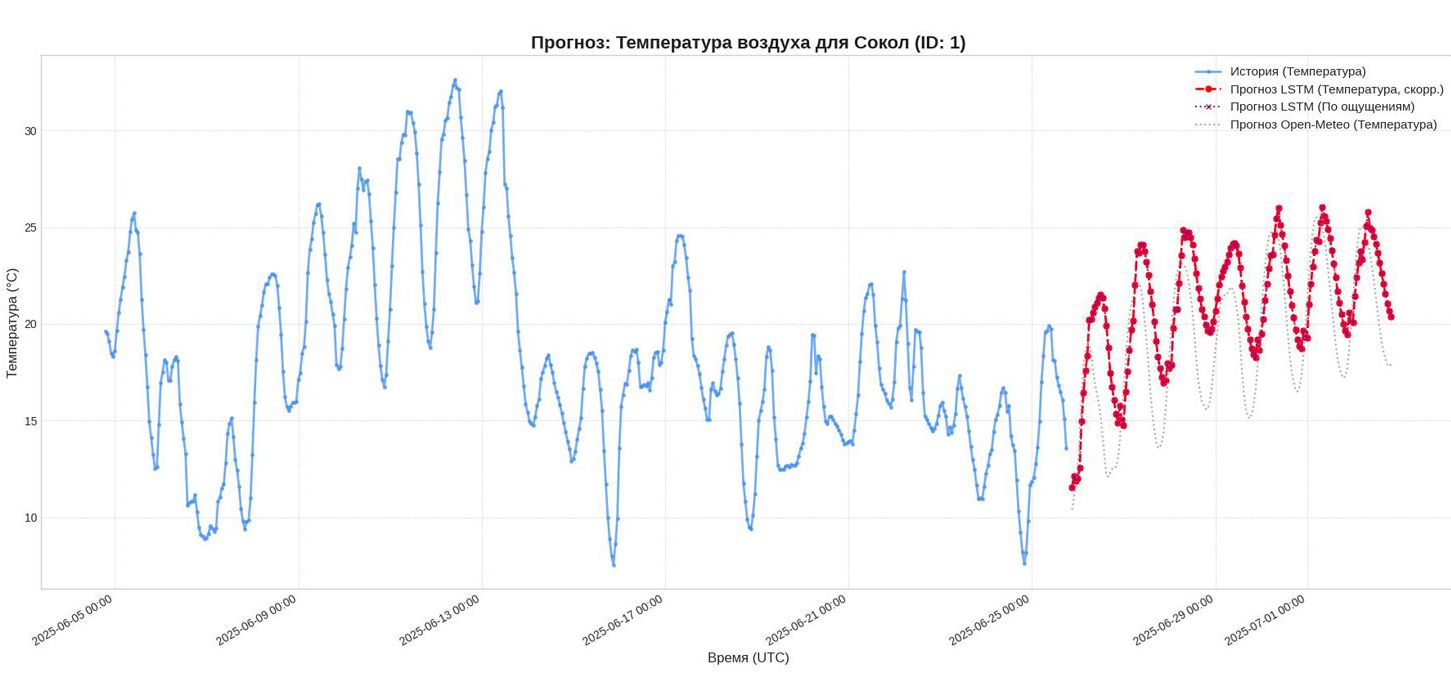
Анализ Графика: Прогноз температуры воздуха
Анализ прогноза "По ощущениям" (Wind Chill или жесткость погоды):
Линии явно не разошлись: Фиолетовая пунктирная линия (Прогноз по ощущениям) еле заметно находится ниже красной (Прогноз LSTM). Это абсолютно правильно. Ветер охлаждает, и ощущаемая температура должна быть ниже реальной. Это настраиваемый параметр (ветро - холодового признака) активация логики от N градусов.
Динамический разрыв: Расстояние между красной и фиолетовой линиями не постоянно — оно то увеличивается, то уменьшается. Это тоже идеально правильно. Это означает, что прогнозируемая скорость ветра меняется, и эффект охлаждения становится то сильнее, то слабее.
Анализ общего прогноза:
Правдоподобность: Сам прогноз (красная линия) выглядит очень реалистично. Он показывает четкие суточные циклы (пики днем, спады ночью) с разной амплитудой, что соответствует реальным погодным условиям.
Сравнение с Open-Meteo (иным бесплатным доступным прогностическим сервисом): Прогноз заметно отличается от базового прогноза Open-Meteo (серая линия). Это хорошо — это доказывает, что модель, обученная на локальных данных, дает уникальный, скорректированный результат.
Опциональная гибридизация:
Механизм коррекции позволяет мягко "подтягивать" высокоточный локальный прогноз к общему региональному прогнозу, но только в тех случаях, когда они начинают слишком сильно расходиться. Это помогает избежать грубых ошибок и делает ваш прогноз более робастным (устойчивым).
Пошаговая формула работы:
Давайте представим, что у нас есть одна точка прогноза. Для нее мы имеем:
lstm_forecast — значение, предсказанное вашей LSTM-моделью.
om_forecast — значение, полученное от Open-Meteo для того же времени.
Вот как работают наши параметры на каждом шаге:
Шаг 1: Расчет разницы (Difference)
Сначала система вычисляет, насколько сильно наш прогноз отличается от прогноза Open-Meteo.
difference = lstm_forecast - om_forecast
Пример: lstm_forecast = 25.0°C, om_forecast = 22.0°C.
difference = 25.0 - 22.0 = 3.0°C. Наш прогноз на 3 градуса выше.
Шаг 2: Проверка порога (Threshold Check)
Далее система проверяет, стоит ли вообще вмешиваться. Если расхождение незначительное, то трогать точный локальный прогноз нет необходимости.
if abs(difference) > CORRECTION_THRESHOLD:
# Продолжаем, если разница существенна
else:
# Ничего не делаем, расхождение в пределах нормы установленной нами
Здесь используется параметр CORRECTION_THRESHOLD = 2.0.
Пример: abs(3.0) > 2.0. Условие истинно. Расхождение в 3 градуса считается существенным, и коррекция будет применена.
Контрпример: Если бы difference было 1.5°C, то abs(1.5) <= 2.0, и коррекция бы не применялась.
Шаг 3: Расчет базовой коррекции (Correction Calculation)
Если порог превышен, система рассчитывает величину, на которую нужно скорректировать ваш прогноз. Она берет разницу и умножает ее на "коэффициент уверенности" или "силу коррекции".
Здесь используется параметр CORRECTION_FACTOR = 0.5
# Важно: коррекция направлена в ПРОТИВОПОЛОЖНУЮ сторону от разницы
base_correction = -difference * CORRECTION_FACTOR
Знак "минус" здесь ключевой. Если ваш прогноз был выше (difference > 0), то коррекция будет отрицательной (уменьшит ваш прогноз). И наоборот.
Пример: base_correction = -3.0 * 0.5 = -1.5°C.
Система решила, что ваш прогноз нужно "подтянуть" вниз на 1.5 градуса
Шаг 4: Ограничение максимальной коррекции (Capping the Correction)
Чтобы избежать слишком резких и потенциально ошибочных изменений, система ограничивает абсолютную величину рассчитанной коррекции.
Здесь используется параметр MAX_CORRECTION = 5.0
# Ограничиваем коррекцию сверху и снизу
final_correction = max(-MAX_CORRECTION, min(MAX_CORRECTION, base_correction))
Эта строка гарантирует, что final_correction никогда не будет больше 5.0 и никогда не будет меньше -5.0.
Пример: final_correction = max(-5.0, min(5.0, -1.5)). Результат — -1.5°C. Наша коррекция находится в пределах лимита.
Контрпример: Если бы base_correction была -7.0°C, то min(5.0, -7.0) вернуло бы -7.0, а max(-5.0, -7.0) вернуло бы -5.0°C. То есть, даже при огромной разнице, прогноз изменится не более чем на 5 градусов.
Шаг 5: Применение финальной коррекции
Последний шаг — применить рассчитанную и ограниченную коррекцию к исходному прогнозу LSTM.
corrected_forecast = lstm_forecast + final_correction
Пример: corrected_forecast = 25.0 + (-1.5) = 23.5°C.
Итоговая формула в одной строке
Если объединить все шаги, то логику можно описать так:
corrected_forecast = lstm_forecast + max(-MAX_CORRECTION, min(MAX_CORRECTION, -(lstm_forecast - om_forecast) * CORRECTION_FACTOR)), но только если abs(lstm_forecast - om_forecast) > CORRECTION_THRESHOLD.
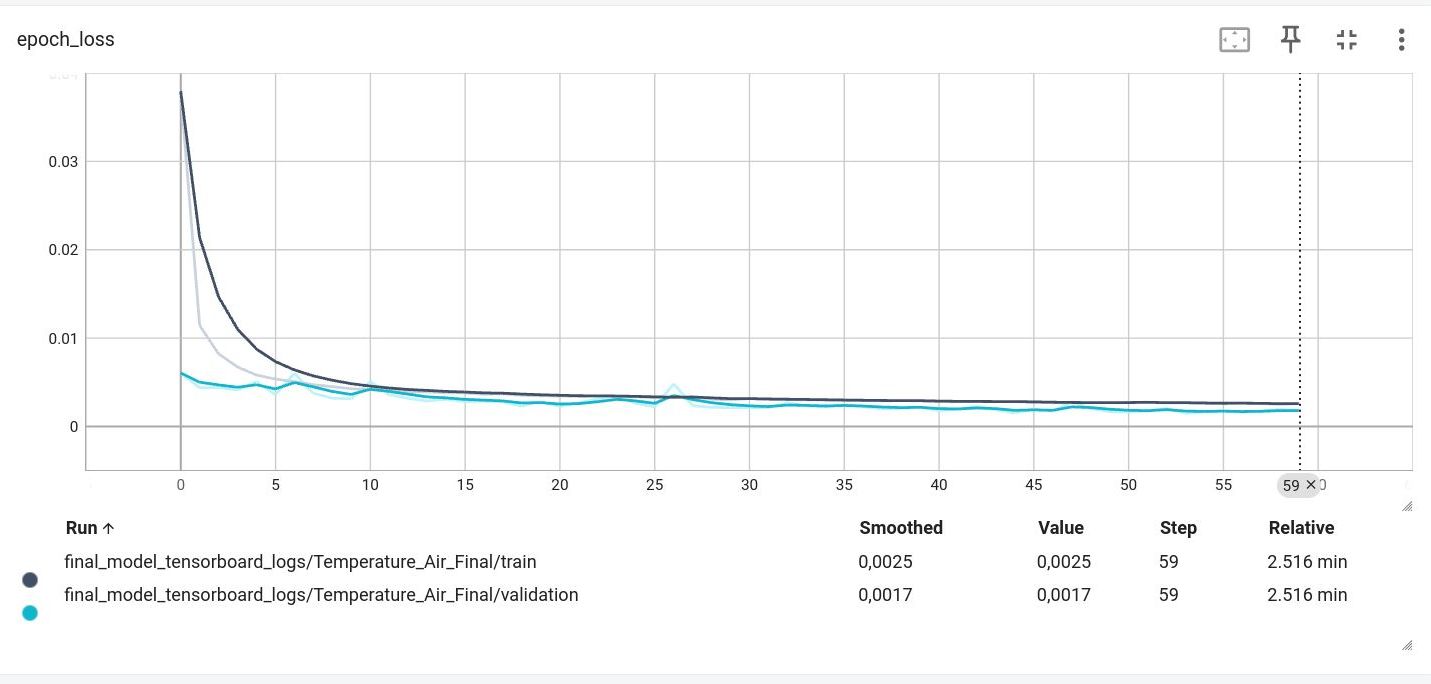
Анализ графика потерь (epoch_loss)
Анализ прогноза "По ощущениям" (Wind Chill или жесткость погоды):
Линии явно не разошлись: Фиолетовая пунктирная линия (Прогноз по ощущениям) еле заметно находится ниже красной (Прогноз LSTM). Это абсолютно правильно. Ветер охлаждает, и ощущаемая температура должна быть ниже реальной. Это настраиваемый параметр (ветро - холодового признака) активация логики от N градусов.
Динамический разрыв: Расстояние между красной и фиолетовой линиями не постоянно — оно то увеличивается, то уменьшается. Это тоже идеально правильно. Это означает, что прогнозируемая скорость ветра меняется, и эффект охлаждения становится то сильнее, то слабее.
Анализ общего прогноза:
Правдоподобность: Сам прогноз (красная линия) выглядит очень реалистично. Он показывает четкие суточные циклы (пики днем, спады ночью) с разной амплитудой, что соответствует реальным погодным условиям.
Сравнение с Open-Meteo (иным бесплатным доступным прогностическим сервисом): Прогноз заметно отличается от базового прогноза Open-Meteo (серая линия). Это хорошо — это доказывает, что модель, обученная на локальных данных, дает уникальный, скорректированный результат.
Опциональная гибридизация:
Механизм коррекции позволяет мягко "подтягивать" высокоточный локальный прогноз к общему региональному прогнозу, но только в тех случаях, когда они начинают слишком сильно расходиться. Это помогает избежать грубых ошибок и делает ваш прогноз более робастным (устойчивым).
Пошаговая формула работы:
Давайте представим, что у нас есть одна точка прогноза. Для нее мы имеем:
lstm_forecast — значение, предсказанное вашей LSTM-моделью.
om_forecast — значение, полученное от Open-Meteo для того же времени.
Вот как работают наши параметры на каждом шаге:
Шаг 1: Расчет разницы (Difference)
Сначала система вычисляет, насколько сильно наш прогноз отличается от прогноза Open-Meteo.
difference = lstm_forecast - om_forecast
Пример: lstm_forecast = 25.0°C, om_forecast = 22.0°C.
difference = 25.0 - 22.0 = 3.0°C. Наш прогноз на 3 градуса выше.
Шаг 2: Проверка порога (Threshold Check)
Далее система проверяет, стоит ли вообще вмешиваться. Если расхождение незначительное, то трогать точный локальный прогноз нет необходимости.
if abs(difference) > CORRECTION_THRESHOLD:
# Продолжаем, если разница существенна
else:
# Ничего не делаем, расхождение в пределах нормы установленной нами
Здесь используется параметр CORRECTION_THRESHOLD = 2.0.
Пример: abs(3.0) > 2.0. Условие истинно. Расхождение в 3 градуса считается существенным, и коррекция будет применена.
Контрпример: Если бы difference было 1.5°C, то abs(1.5) <= 2.0, и коррекция бы не применялась.
Шаг 3: Расчет базовой коррекции (Correction Calculation)
Если порог превышен, система рассчитывает величину, на которую нужно скорректировать ваш прогноз. Она берет разницу и умножает ее на "коэффициент уверенности" или "силу коррекции".
Здесь используется параметр CORRECTION_FACTOR = 0.5
# Важно: коррекция направлена в ПРОТИВОПОЛОЖНУЮ сторону от разницы
base_correction = -difference * CORRECTION_FACTOR
Знак "минус" здесь ключевой. Если ваш прогноз был выше (difference > 0), то коррекция будет отрицательной (уменьшит ваш прогноз). И наоборот.
Пример: base_correction = -3.0 * 0.5 = -1.5°C.
Система решила, что ваш прогноз нужно "подтянуть" вниз на 1.5 градуса
Шаг 4: Ограничение максимальной коррекции (Capping the Correction)
Чтобы избежать слишком резких и потенциально ошибочных изменений, система ограничивает абсолютную величину рассчитанной коррекции.
Здесь используется параметр MAX_CORRECTION = 5.0
# Ограничиваем коррекцию сверху и снизу
final_correction = max(-MAX_CORRECTION, min(MAX_CORRECTION, base_correction))
Эта строка гарантирует, что final_correction никогда не будет больше 5.0 и никогда не будет меньше -5.0.
Пример: final_correction = max(-5.0, min(5.0, -1.5)). Результат — -1.5°C. Наша коррекция находится в пределах лимита.
Контрпример: Если бы base_correction была -7.0°C, то min(5.0, -7.0) вернуло бы -7.0, а max(-5.0, -7.0) вернуло бы -5.0°C. То есть, даже при огромной разнице, прогноз изменится не более чем на 5 градусов.
Шаг 5: Применение финальной коррекции
Последний шаг — применить рассчитанную и ограниченную коррекцию к исходному прогнозу LSTM.
corrected_forecast = lstm_forecast + final_correction
Пример: corrected_forecast = 25.0 + (-1.5) = 23.5°C.
Итоговая формула в одной строке
Если объединить все шаги, то логику можно описать так:
corrected_forecast = lstm_forecast + max(-MAX_CORRECTION, min(MAX_CORRECTION, -(lstm_forecast - om_forecast) * CORRECTION_FACTOR)), но только если abs(lstm_forecast - om_forecast) > CORRECTION_THRESHOLD.
Анализ графика потерь (epoch_loss)
Что мы видим:
Темно-серая линия (train): Ошибка на обучающих данных.
Голубая линия (validation): Ошибка на валидационных (тестовых) данных, которые модель не использовала для подстройки весов.
Ключевые выводы:
Быстрая сходимость: Обе кривые очень резко падают в первые 5-10 эпох. Это означает, что модель быстро улавливает основные закономерности в данных.
Отсутствие переобучения (Overfitting): Это самый важный вывод. Переобучение происходит, когда ошибка на обучающих данных продолжает падать, а на валидационных начинает расти (кривые расходятся). мы не наблюдаем, наоборот, обе кривые идут почти параллельно друг другу до самого конца. Это говорит о том, что модель учит общие паттерны, а не просто "зазубривает" обучающую выборку.
Валидационная ошибка НИЖЕ обучающей: Обратите внимание, что голубая линия (validation) почти всегда находится ниже серой (train). Это не является ошибкой, а очень хороший знак! Такое часто происходит, потому что мы используем техникурегуляризации, в т.ч. такую как Dropout. Во время обучения Dropout случайным образом "отключает" часть нейронов, усложняя модели задачу. А во время валидации все нейроны работают, и модель показывает свой полный потенциал. То, что она работает на незнакомых данных даже лучше, чем на обучающих (на которых ей мешал Dropout), — признак превосходной обобщающей способности.
Выход на плато: После примерно 20-й эпохи обе кривые становятся очень пологими. Это означает, что модель достигла своего пика производительности для данной архитектуры и данных. Дальнейшее обучение (например, до 200 эпох) почти не принесло бы улучшения и было бы пустой тратой времени. Выбранное количество эпох (~60) является оптимальным.
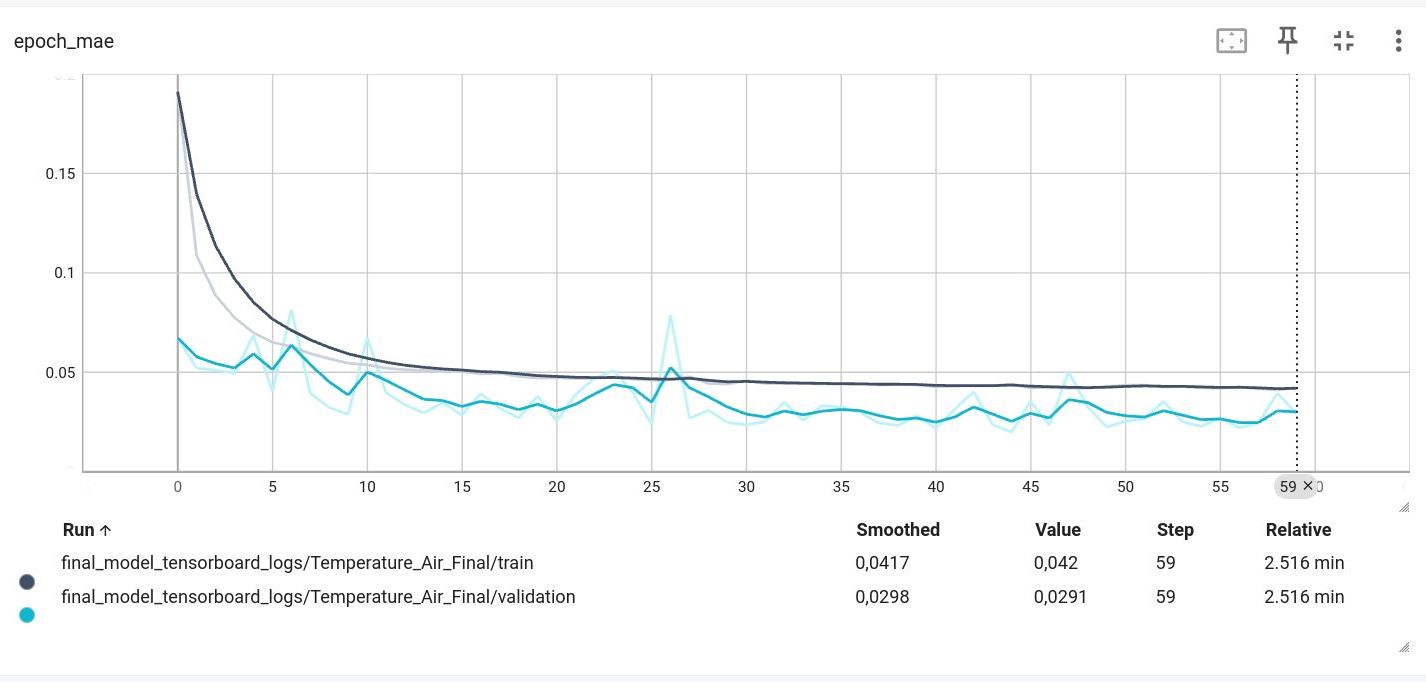
Анализ графика метрики MAE (epoch_mae)
Что мы видим:
Темно-серая линия (train): Средняя абсолютная ошибка (MAE) на обучающих данных.
Голубая линия (validation): MAE на валидационных данных.
Ключевые выводы:
Повторение динамики Loss: График MAE почти полностью повторяет график потерь, что логично, так как MAE является одной из ключевых метрик для оценки.
Интерпретация значений:
Конечное значение validation MAE (в масштабированных единицах) составляет ~0.0298.
Это значение после обратного масштабирования и дает ту самую ошибку в ~0.38°C, которую мы видели на предыдущем графике. Графики полностью согласуются.
"Шумность" валидационной кривой: Обратите внимание, что голубая линия MAE более "зубчатая" и "шумная", чем серая. Особенно заметны небольшие "всплески" вверх (например, в районе 25-й эпохи).
Что это значит? Это абсолютно нормально. Обучающая метрика усредняется по множеству батчей внутри одной эпохи, поэтому она более гладкая. Валидационная метрика считается на одном и том же, более маленьком наборе данных в конце каждой эпохи. Ее "скачки" показывают, что некоторые обновления весов делают модель чуть лучше для этого конкретного набора данных, а некоторые — чуть хуже.
Связь с предыдущим графиком: Эта "нервозность" валидационной кривой может быть предвестником той нестабильности, которую вы наблюдали в самом конце графика производительности (где прогноз начал "скакать"). Это говорит о том, что модель, хоть и очень точная в среднем, может быть чувствительна к определенным, более "сложным" участкам данных особенно в "рваной" истории с провалами данных.
Что мы видим:
Темно-серая линия (train): Средняя абсолютная ошибка (MAE) на обучающих данных.
Голубая линия (validation): MAE на валидационных данных.
Ключевые выводы:
Повторение динамики Loss: График MAE почти полностью повторяет график потерь, что логично, так как MAE является одной из ключевых метрик для оценки.
Интерпретация значений:
Конечное значение validation MAE (в масштабированных единицах) составляет ~0.0298.
Это значение после обратного масштабирования и дает ту самую ошибку в ~0.38°C, которую мы видели на предыдущем графике. Графики полностью согласуются.
"Шумность" валидационной кривой: Обратите внимание, что голубая линия MAE более "зубчатая" и "шумная", чем серая. Особенно заметны небольшие "всплески" вверх (например, в районе 25-й эпохи).
Что это значит? Это абсолютно нормально. Обучающая метрика усредняется по множеству батчей внутри одной эпохи, поэтому она более гладкая. Валидационная метрика считается на одном и том же, более маленьком наборе данных в конце каждой эпохи. Ее "скачки" показывают, что некоторые обновления весов делают модель чуть лучше для этого конкретного набора данных, а некоторые — чуть хуже.
Связь с предыдущим графиком: Эта "нервозность" валидационной кривой может быть предвестником той нестабильности, которую вы наблюдали в самом конце графика производительности (где прогноз начал "скакать"). Это говорит о том, что модель, хоть и очень точная в среднем, может быть чувствительна к определенным, более "сложным" участкам данных особенно в "рваной" истории с провалами данных.
Резюмируя производительность модуля прогнозирования временных рядов уверенно утверждаем основываясь исключительно на фактах - производительность нашего "Комбайна" великолепная!
Метеорология и экология
Модуль прогнозирования временных рядов от Краммерти является иструментом и вводя дополнительные коррелирующие признаки к метео параметрам, усложняя и делая систему более умной и гибкой за счет добавления дополнительных признаков данный инструмент применяется в том числе и для прогнозирования метеорологических параметров.
Философский камень ..
Мы не рассуждаем о философском камне прогнозирования параметров стихий - погодных условий, мы говорим и показываем факты прогнозирования данных во времени с использованием инструмента - программное обеспечение Краммерти. Модуль прогнозирования временных рядов.
Мы не рассуждаем о философском камне прогнозирования параметров стихий - погодных условий, мы говорим и показываем факты прогнозирования данных во времени с использованием инструмента - программное обеспечение Краммерти. Модуль прогнозирования временных рядов.
Перспективные сферы применения описаны в документации к программному обеспечению.
Любые адаптации и внедрения включая разработку графических интерфейсов под Ваши задачи - выполняем.
Есть временные ряды - есть прогноз!
Продажа и внедрение программных продуктов 1-С Битрикс Управление сайтом, 1С-Битрикс24


Программы Фирмы "1С"
ООО "Краммерти" является франчайзи Фирмы "1С"
Внедряем программные продукты "1С" на Вашем предприятии.
Виджет подбора программ "1С" - оформите счет-КП на программу "1С" в два клика
Супермаркет программ Фирмы "1С", торгового оборудования и программного обеспечения Партнеров Фирмы "1С"
Стоимость работ специалистов: от 3 000 руб./час
на все выполняемые работы предоставляем письменную гарантию.
Продаем, обновляем и обслуживаем официальные лицензионные продукты фирмы "1С"
Официальный партнер
Программы системы "1С:Предприятие" распространяются через сеть партнерских организаций во всех регионах России и во многих странах.
Компания Краммерти входит в сеть "1С:Франчайзинг" и является официальным партнером, решаем комплексные задачи по автоматизации учетной и офисной работы
Компания Краммерти входит в сеть "1С:Франчайзинг" и является официальным партнером, решаем комплексные задачи по автоматизации учетной и офисной работы
От помощи в выборе программных средств, их продажи, установки и настройки до постановки на предприятии учета в полном объеме.
ООО "Краммерти" 2023-2025 ©
Политика конфиденциальности
Политика конфиденциальности
Для повышения удобства работы с сайтом ООО "Краммерти" использует файлы cookie. В cookie содержатся данные о прошлых посещениях сайта. Если вы не хотите, чтобы эти данные обрабатывались, отключите cookie в настройках браузера.
Телефон:
+7 (922) 078-99-44
Адрес офиса:
ХМАО-Югра, г.Сургут,
ул.Юности, 8
Электронная почта:
krammerti@yandex.ru
Телеграм